本文介绍了 python 内部是如何管理字符串对象,以及字符串查找操作是如何实现的。
PyStringObject 结构体
Python 中的字符串对象在内部对应一个名叫 PyStringObject 的结构体。“ob_shash” 对应字符串经计算过的 hash值, “ob_sval” 指向一段长度为 “ob_size” 的字符串,且该字符串以‘null’结尾(为了兼容C)。“ob_sval”的初始大小为1个字节,且 ob_sval[0]=0(对应空字符串)。若你还想知道“ob_size”被定义的位置,可以看一看 object.h 头文件中 PyObject_VAR_HEAD 对应部分。“ob_sstate” 用来指示某个字符串是否已经存在于intern机制对应的字典中,后面我们会再次提到这一点。
typedef struct {
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
} PyStringObject;字符串对象的创建
如下所示,当将一个新的字符串赋给一个变量时,发生了什么?
1>>> s1 = 'abc'
运行以上代码时,内部的 C 函数 “PyString_FromString” 将被调用并生成类似下面的伪代码:
arguments: string object: 'abc' returns: Python string object with ob_sval = 'abc' PyString_FromString(string): size = length of string allocate string object + size for 'abc'. ob_sval will be of size: size + 1 copy string to ob_sval return object
每次用到新的字符串时,都将分配一个字符串对象。
共享字符串对象
Python 有一个优雅的特性,就是变量之间的短字符串是共享的,这一特性可以节省所需的内存空间。短字符串就是那些长度为 0 个或者 1 个字节的字符串。而全局变量 “interned” 对应一个用于索引这些短字符串的字典。数组 “characters” 也可用于索引那些长度为 1 个字节的字符串,比如单个字母。后面我们将看到数组 “characters” 是如何被使用的。
static PyStringObject *characters[UCHAR_MAX + 1]; static PyObject *interned;
下面一起看看:当你在 Python 脚本中将一个短字符串赋值给一个变量时,背后发生了哪些事情。
static PyStringObject *characters[UCHAR_MAX + 1]; static PyObject *interned;
内容为 ‘a’ 的字符串对象将被添加到 “interned” 字典中。字典中键(key)是一个指向该字符串对象的指针,而对应的值 就是一个相同的指针。在数组 “characters” 中,这一新的字符串对象在偏移量为 97 的位置被引用,因为字符 ‘a’ 的ASCII码值便是 97。变量 “s2” 也指向了这一字符串对象。
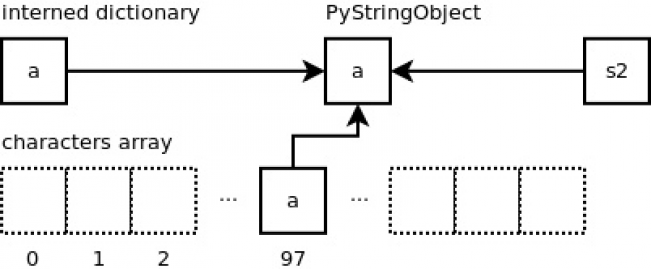
而,当另外一个变量也被相同的字符串 ‘a’ 赋值时,又会如何呢?
1>>> s3 = 'a'
上述代码执行后,将返回之前已创建的内容相同的字符串对象。因此,‘s1’ 和 ‘s3’ 两个变量都将指向同一个字符串对象。 数组 “characters” 便是用于检测字符串 ‘a’ 是否已经存在,若存在,则返回指向该字符串对象的指针。
if (size == 1 && (op = characters[*str & UCHAR_MAX]) != NULL)
{
...
return (PyObject *)op;
}
下面我们新建一个内容为 ‘c’ 的短字符串:
1>>> s4 = 'c'
那么,我们将得到如下结果:
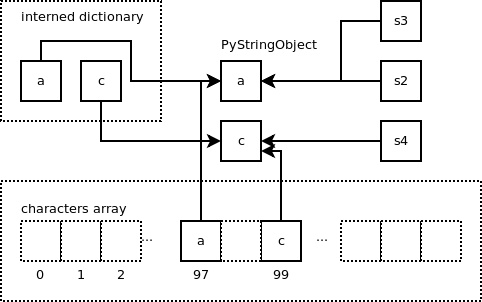
我们还能发现,当按照下面 Python 脚本中的方式对一个字符串元素进行访问时,数组 “characters” 仍有用武之地。
>>> s5 = 'abc' >>> s5[0] 'a'
上面第二行代码中,返回的是数组 “characters” 偏移量为 97 的位置内的指针元素,而非新建一个值为 ‘a’的字符串。当我们访问某个字符串中的元素时,一个名叫 “string_item” d的函数将被调用,下方给出了函数体代码。其中,参数 ‘a’ 便对应着字符串 “abc”,而参数 ‘i’ 便是访问数组的索引值(本例中便为 0 ),函数返回的是指向某个字符串对象的指针。
static PyObject *
string_item(PyStringObject *a, register Py_ssize_t i)
{
char pchar;
PyObject *v;
...
pchar = a->ob_sval[i];
v = (PyObject *)characters[pchar & UCHAR_MAX];
if (v == NULL)
// allocate string
else {
...
Py_INCREF(v);
}
return v;
}数组 “characters” 也可用于函数名长度为 1 时的情形,如下所示:
>>> def a(): pass
字符串查找
下面看看,当你在如下 Python 代码中进行字符串查找操作时,又会有那些事情发生呢?
>>> s = 'adcabcdbdabcabd'
>>> s.find('abcab')
>>> 11函数 “find” 返回一个索引值,说明是在字符串 “abcd” 的哪个位置找到字符串 “s” 的。若字符串未找到,函数返回值为 -1。
那么,内部到底干了些啥事情?内部调用了一个名为 “fastsearch” 的函数。这个函数是一个介于 BoyerMoore 和 Horspool 算法之间的混合版本,它兼具两者的优良特性。
我们将 “s”(s = ‘adcabcdbdabcabd’)称作主字符串,而将 “p”(p = ‘abcab’)称作模式串。n 和 m 分别表示字符串 s 和 字符串 p 的长度,其中,n = 15, m = 5。
在如下代码段中,明显看到,程序将进行首次判定:若 m > n,我们就知道必然不能找到这样的索引号,因此函数直接返回 -1 即可。
w = n - m; if (w < 0) return -1;
当 m = 1 时,程序便在字符串 s 中一个个字符地进行遍历,若匹配成功则返回对应的索引位置。在本例中,变量 mode 值为 FAST_SEARCH,意味着我们想获取的是在主字符串中首次匹配的位置,而非模式串在主字符串中成功匹配的次数。
if (m <= 1) {
...
if (mode == FAST_COUNT) {
...
} else {
for (i = 0; i < n; i++)
if (s[i] == p[0])
return i;
}
return -1;
}考虑其他情况,比如 m > 1。首先创建一个压缩的boyer-moore delta 1 table(对应BM算法中的坏字符规则),在此过程中需要声明两个变量:“mask” 和 “skip”。
“mask” 是一个 32 位的位掩码(bitmask),将其最低的 5 个特征位作为开关位。该掩码是通过和模式串 “p” 进行操作产生的。它设计成一个布隆过滤器(bloom filter),用于检测一个字符是否出现在当前字符串中。这种机制使查找操作十分迅速,但是存在伪正的情况(false positives)。关于布隆过滤器,你想有更多了解的话可以看看 这里 。对于本例,下方说明了位掩码具体是如何产生的。
mlast = m - 1
/* process pattern[:-1] */
for (mask = i = 0; i < mlast; i++) {
mask |= (1 << (p[i] & 0x1F));
}
/* process pattern[-1] outside the loop */
mask |= (1 << (p[mlast] & 0x1F));字符串 “p” 的第一个字符为 ‘a’。字符‘a’的二进制表示为 97 = 1100001。保留最低的 5 个特征位,我们得到了 00001,因此变 “mask” 初次被设定为 10(1 << 1)。当整个字符串 “p” 都经过处理后,mask 值为 1110。那么,我们应该如何使用这个位掩码呢?通过下方这行代码,我们用其来检测字符 “c” 位于字符串 “p” 哪个位置。
if ((mask & (1 << (c & 0x1F))))
那么,字符 ‘a’ 在字符串 “p”(‘abcab’)中是否存在呢?1110 & (1 << (‘a’ & 0X1F)) 运算结果的值是否为 true 呢?由于 1110 & (1 << (‘a’ & 0X1F)) = 1110 & 10 = 10,可知 ‘a’ 确实存在于 ‘abcab’。当检测字符 ‘d’时,我们得到的是 false,对于其他字符(从 ‘e’ 到 ‘z’)也是同样结果。因此,在本例中此类过滤器表现十分出众。 变量 “skip” 对应目标字符在主字符串中最后一个成功匹配的字符的索引位置(从后向前匹配)。假若模式串的最后一个匹配字符在主字符串中不存在,则 “skip” 值为 模式串 “p” 的长度减去 1。本例中,模式串最后一个为匹配字符位 ‘b’,由于其在主串查找的当前位置向后跳两个字符后能够匹配到,因此变量 “skip” 的值为2。这个变量应用于一种名叫坏字符跳跃(bad-character skip)的规则。在如下示例中,p = ‘abcab’,s = ‘adcabcaba’。从主串 “s” 的 4 号索引位置(从 0 开始计算)开始匹配,若字符匹配成功则向前继续匹配。第一个匹配失败的索引位置为 1(此处 ‘b’ 不等于 ‘d’)。我们可以看到,在模式串和主串最开始匹配的末端位置往后数三个字符,主串中也有一个 ‘b’,而字符 ‘c’ 也存在于 “p” 中,因此我们跳过了随后的 ‘b’。
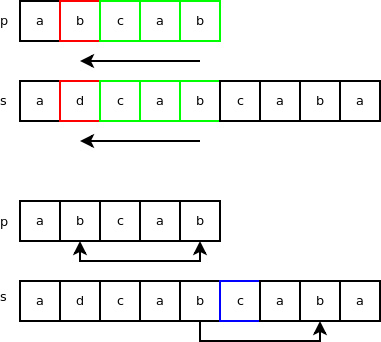
下面,看下查找操作的循环部分(真实代码为 C 实现,而非 Python):
for i = 0 to n - m = 13: if s[i+m-1] == p[m-1]: if s[i:i+mlast] == p[0:mlast]: return i if s[i+m] not in p: i += m else: i += skip else: if s[i+m] not in p: i += m return -1
“s[i+m] not in p” 这行测试代码是基于位掩码实现的,“i += skip” 便对应坏字符跳跃。当主串下一个待匹配的字符在 “p” 中并未找到时,则执行 “i += m” 这行代码。
下面来看看,对于字符串 “p” 和 “s” 的匹配,算法具体是如何运行的。前三个步骤与上面类似,接着,字符 ‘d’ 在字符串 “p” 并未找到,因此我们直接跳过等于“p”字符串长度的字符数,之后便迅速找到了一个匹配。
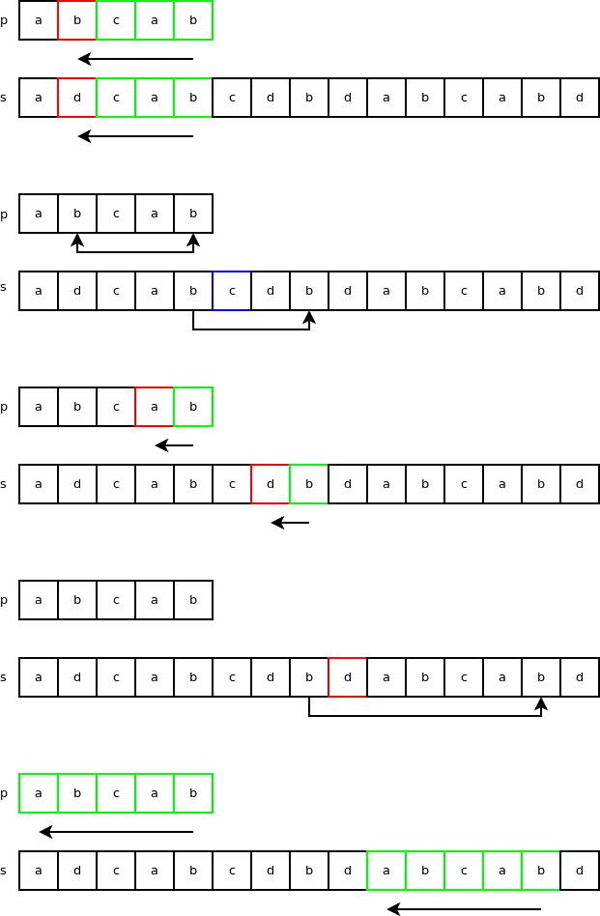
有关Python字符串对象完整的代码实现, 去这里看看(http://svn.python.org/projects/python/trunk/Objects/stringobject.c) 。
http://developer.51cto.com/art/201706/542368.htm

最新评论: