背景
随着大数据不断地融入到工作中,如何使大量的数据资产变现,并提供有价值的见解,通过大量的历史数据和实时数据作为业务工作的参考预测未来,驱动业务的发展,需要统一数据平台来满足用户工作的需求。
一、为什么要做?
平台建立之前,我们主要依赖各种不同的数据工具来处理团队数据需求。随着业务的发展,数据在工作中作用越来越大,但不同工具各自独立引起的数据问题也越来越严重。酒店数据智能平台的起源,当时主要从以下几个现实痛点出发:
散:数据分散在不同平台,没有地方可以统一查看所有数据;
杂:不同平台逻辑不同,没有统一评判标准;
浅:数据明细不够直观深入,无法清楚地了解趋势及问题;
慢:查询速度慢,临时取数流程漫长;
晚:当时存在的数据报表平台都无法实现实时的数据监控,对于业务在工作中,特别是订单高峰期库存时刻在变化的时候,不能起到很好的指导和推动作用;
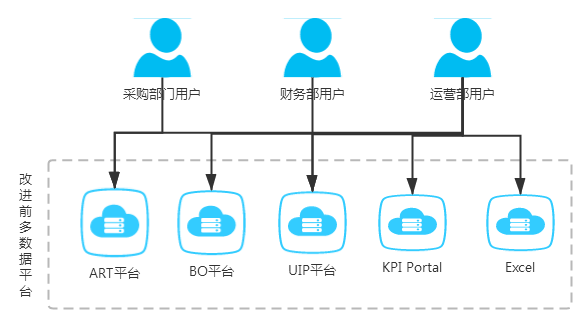
下图是平台创建之前的工作方式,不同的部门在很多个数据平台获取各种数据:
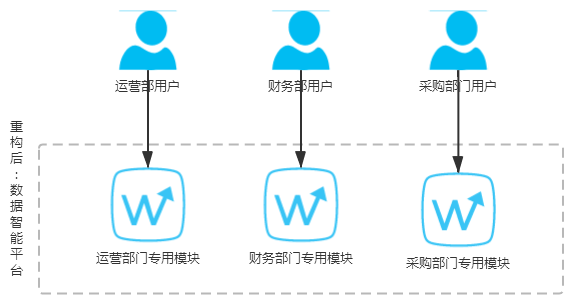
下图是平台创建之后,每个部门都用同一份数据,整个平台的各种指标逻辑统一:
平台的创建起步数据引擎采用的是多节点SQL服务器为主,ElasticSearch为辅的方式,但同样遇到了大多数数据平台的通病,数据量太大,数据表多,查询性能差,各种问题防不胜防,主要问题集中在以下几点:
1)数据量日积月累越来越大,哪怕sharding也很难实现到查询秒出,并且硬件成本和程序复杂度都很高;
2)数据查询涉及逻辑复杂,单个SQL往往涉及多个表join,以致SQL执行慢,SQL优化难度大;
3)历史数据更新量大,普通的SQL数据库数据导入都会存在io瓶颈;
4)搜索条件多,汇总维度不固定,导致很多数据无法更进一步汇总;
5)同时在线用户量很高,特别是针对业绩数据,实时订单数据和奖金数据等场景是业务非常关心的,所以这些case的并发量非常高;
6)接口性能不稳定,数据更新时接口性能波动大;
二、如何做?
针对上述问题,我们需要解决平台的查询性能,高并发以及每天大量的数据更新时用户端应用的高可用,同时我们的性能响应时间指标是pc端小于3秒,app端小于1秒。
为此,我们尝试了很多种数据库,考虑过相互之间尽量互补,各取所长。经过多次测试,实践得出每个数据库应用于我们场景的结论:
1)ClickHouse 查询速度快,但无法承受高并发;
2)ElasticSearch 查询速度快,cpu消耗到60%对查询性能不会有太大的影响,但不能做多表join,大宽表维护成本不现实,约束了我们的使用场景;
3)Ingite 虽然也是内存数据库,但性能在高并发的时候内存会打爆,不能满足我们的要求,这个是用5台24G内存的虚拟机测试结果;
4)Presto 查询时直接读取hive表,能减少数据同步的流程,降低开发成本,查询速度勉强能接受,但不能满足高可用。因此这个只针对我们团队内部应用场景,不对业务端需求采用该技术方案;
5)CrateDB底层沿用了ElasticSearch的源码,支持SQL语法,比ElasticSearch的使用更友好,也解决了es不能join的问题,但在多表join的场景qps达到20个左右内存就会被打爆(6台8核24G内存虚拟机测试场景),单表查询性能和高并发支撑还是可以的;
6)MongoDB 走索引查询速度非常快,但太依赖左侧原则,也不能join,只能通过嵌套文档的方案解决join的问题,但我们的查询条件太多,不能强依赖左侧原则来查询;
其他还有Hbase,Kylin,Garuda等等,每个数据库我们都有搭建环境压测,每个数据库从硬件成本,性能上都有自己特有的优势,综合到使用场景,暂时最适合我们的还是ClickHouse。
ClickHouse在去年的文章《每天十亿级数据更新,秒出查询结果,ClickHouse在携程酒店的应用》中有介绍,虽然它很快,但也有缺点,特别是高并发场景。只要出现瓶颈会很快出现恶性循环,查询请求积压,连接数打满,cpu使用率直线上升。所以ClickHouse会作为一个主力引擎来承受查询请求,充分的利用它的优势,但也需要对它有足够的保护。
实践中我们总结了以下方式来优化接口性能同时起到保护ClickHouse的作用:
1)做好查询监控,针对每个接口,每个查询语句都能知道查询消耗时间,case by case优化;
2)所有数据查询请求拆成异步请求,避免大接口中数据请求等待的过程影响数据展示的速度;
3)针对使用率很高数据量又非常大的表,可以创建一个全量表,同时也创建一个只有最近6个月数据的表。因为我们通过埋点发现,90%以上的查询都主要集中在查最近6个月的数据。所以有90%以上的查询使用的表数据量远远小于全量表,性能会好很多,服务器的开销也会小很多。当然这个方案也是需要case by case看的,也许某些case用户访问量最高的数据集中在最近3个月,可以根据实际情况来定;
4)统计出日常调用量比较大的接口,有针对性的做如下优化:
固定缓存:如果数据固定范围或者对于访问量高的页面默认查询条件,数据当天更新后由job触发主动模拟用户查询,提前为用户把数据缓存到redis中。用户在上班时间段查询就会从redis中拿数据,性能提高了,ClickHouse的压力也降低了,也避免了用户高峰期间集中查询对ClickHouse服务器的冲击。
动态缓存:如果数据范围不固定,但调用量也很大,特别是实时数据,为了ClickHouse的稳定性,也建议增加缓存。我们曾经在这里踩过坑,用户会用同样的条件不断的刷数据,也许他在期待业绩数据的变化,遇到高并发的时候会把ClickHouse服务器CPU打满。实际上通过埋点发现,哪怕缓存时间只有3分钟也可以降低50%以上的ClickHouse查询请求。
分流机制:ClickHouse主要是解决我们大表join查询性能,实际应用中可以将一些场景拆解,比如一些一线业务的权限比较小,对应权限的酒店数据量也会比较小。我们可以定义一个阀值,比如小于5000或者8000的数据走mysql,这部分人走mysql速度也会很快,让权限大的用户走ClickHouse,这样会引流很大一部分用户,提升整个平台的查询性能。
数据平台每天都有大量的数据更新,如何保证线上几百个接口不会随着数据量的增加性能降低,如何保证2000多个数据流程准点更新完数据,如何保证平台的高可用,下面是我们针对一些潜在问题的监控和解决方案:
1)流程监控机制:当前整个平台100多亿的数据量,每天需要更新几十亿的历史数据,2000多个数据更新流程,我们需要保证数据每天能按时更新到ClickHouse中,所以我们做了很多监控。包括最晚截止时间未执行的预警,数据量不一致的预警,ClickHouse数据切换异常预警,都会通过oncall电话或者手机短信通知到我们。
2)当某一个节点出现问题的时候,能将查询请求快速转移到健康的服务器上,对于redis/mysql/es我们公司有健全的DR机制和故障转移机制。对于ClickHouse,我们是将不同的机房服务器构建成虚拟集群,比如A机房一台服务器与B机房一台服务器构建成一个集群,通过程序控制将查询请求打散分布到两台服务器上实现负载均衡。如果A机房有异常或者某一台服务器有异常,只需要配置对应的虚拟集群把对应机器设置下线后人工介入处理。
3)需要有风险意识,由监控抓出对服务器CPU/IO消耗大的查询语句或者数据流程。当服务器CPU使用率突然增加20%或者服务器CPU持续消耗超过20%,我们都会抓出当前正在执行的语句同时发出预警邮件,类似于dump做事后分析。同时开发过程中每个人都需要有意识的关注每个功能的数据量,当遇到数据量大或者访问量大的复杂需求,需要做好缓存,埋点监控以及降级方案。
4)需要有数据校验机制,因为DR机制我们的数据是多写,可能会因为某次网络异常引发两边数据不一致的情况。虽然这种概率很低,但有了校验机制可以及时发现并解决这类问题。
5)异常预警:上线的每一个功能,所有报错都会发邮件通知整个开发组。这样就需要控制程序中的每一个异常,每个报错都需要case by case分析并解决掉,同时也需要对我们自己的开发质量有足够的信心。
下面是系统架构图:
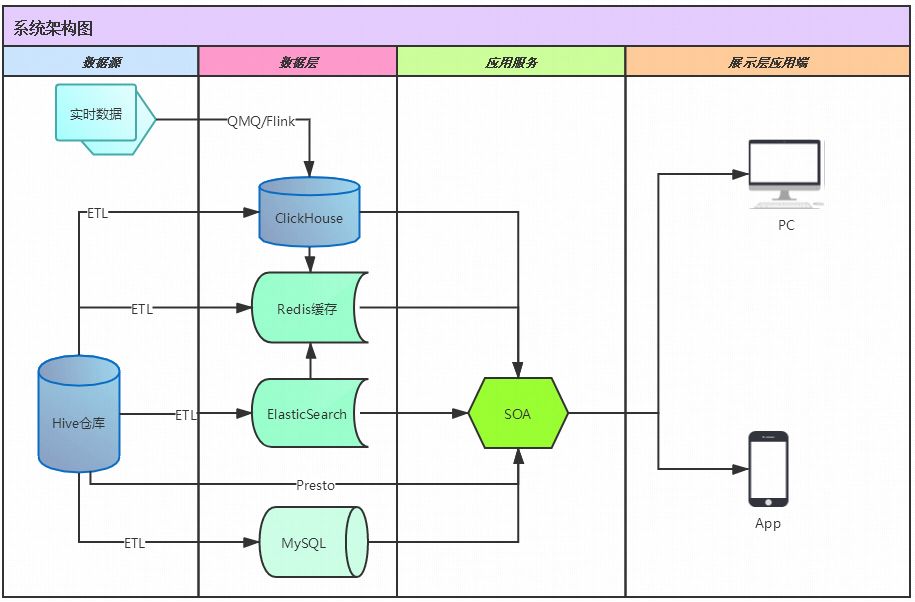
现在整个平台架构由多个虚拟集群组成,随着业务量的增长或者某个集群出现负载压力,可以动态配置新的虚拟集群无限横向扩展满足业务增长需求,也可以将资源利用率低的A集群中的服务器拉入B集群同时分担A,B集群流量。
现在总平台数据量是100多亿,每天有2000多个数据流程运行,需要更新历史数据几十亿。工作日平台每天有2000多在线用户,50多万次的数据查询,调用ClickHouse的次数达到了300多万次。每天有40%左右的请求主要落在数据量比较大的业绩数据,用户行为表上,都是好几亿级业务数据需要join几千万的权限表加千万级的信息表实时计算。
通过下图的监控统计截图可以看到,平台接口1s内响应时间占比在不断提高,超过1s的请求经过优化后占比也是不断的降低。
2019/5/3 | 2019/8/3 | 2019/12/3 | |
<1s占比 | 75.14% | 82.25% | 93.33% |
1s到3s | 24.15% | 17.28% | 6.43% |
超过3s | 0.71% | 0.47% | 0.24% |

上面主要是从服务端介绍了整个系统,其实从前端我们也做了很多工作,因为纯数据的呈现可能会让人觉得枯燥,或者无法直观的从数据中发现问题。
1)整个平台无论多少功能,所有页面加载采用异步请求。用户在浏览任何页面时,系统不会出现白屏式页面刷新,主要是为了避免用户在关注某个数据的时候因为页面刷新而影响到用户分析数据的思路。
2)如何让用户在茫茫的数据海洋中高效的找到关键数据,我们集成了第三方插件做出一些新颖的图像,宏观的分析数据趋势以及关键类型的汇总占比,让用户通过图形展示能更加直观快速得到数据信息。同时我们修改了echart和highchart相关插件源码,自定义默认的颜色体系,自定义指标的刻度值,通过这些前端的修改,可以提高前端视觉体验。也针对常用图形控件做了一层封装,提高前端的开发效率,降低了开发人员前端技能门槛。
三、后期规划
本文主要介绍如何解决数据可视化平台的性能问题,如何保证数据产品的高可用,以及从技术角度如何让数据更直观。2019年我们的主要侧重点是将sql上的数据迁移到clickhouse并优化查询性能,现在90%以上的数据都在clickhouse上,而es,redis,mysql都是在不同的case辅助clickhouse,性能和稳定性有了较大的提升。
今年持续监控,优化性能,同时关注点会适当的下沉到dw,一起完善可视化的上游流程依赖,尽可能的使整个数据生态链更简洁,运行更快更稳定。同时完善平台功能,打通与其他系统之间的交互,加强数据系统与业务系统的关联,通过不断的完善提升数据对业务的帮助。
https://mp.weixin.qq.com/s/OFOa3DrBOiYHf1yQOFva4w

最新评论: