1、为什么一定要设一个主键?
2、你们主键是用自增还是UUID?
3、自增主机用完了怎么办?
4、主键为什么不推荐有业务含义?
5、货币字段用什么类型??
6、时间字段用什么类型?
7、为什么不直接存储图片、音频、视频等大容量内容?
8、表中有大字段X(例如:text类型),且字段X不会经常更新,以读为主,那么是拆成子表好?还是放一起好?
9、字段为什么要定义为NOT NULL?
10、where执行顺序是怎样的
11、应该在这些列上创建索引?
12、mysql联合索引?
13、什么是最左前缀原则?
14、什么情况下应不建或少建索引?
15、MySQL数据库cpu飙升到100%的话他怎么处理?
一、数据库字段设计
1:为什么要一定要设置主键?
其实这个不是一定的,有些场景下,小系统或者没什么用的表,不设置主键也没关系,mysql最好是用自增主键,主要是以下两个原因:果定义了主键,那么InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则innodb 会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则innodb 会选择内置6字节长的ROWID作为隐含的聚集索引。所以,反正都要生成一个主键,那你还不如自己指定一个主键,提高查询效率!
2:主键是用自增还是UUID?
最好是用自增主键,主要是以下两个原因:
1. 如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。
2. 如果使用非自增主键(如uuid),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到索引页的随机某个位置,此时MySQL为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成索引碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
不过,也不是所有的场景下都得使用自增主键,可能场景下,主键必须自己生成,不在乎那些性能的开销。那也没有问题。
3:自增主机用完了怎么办?
在mysql中,Int整型的范围(-2147483648~2147483648),约20亿!因此不用考虑自增ID达到最大值这个问题。而且数据达到千万级的时候就应该考虑分库分表了。
4:主键为什么不推荐有业务含义?
最好是主键是无意义的自增ID,然后另外创建一个业务主键ID,
因为任何有业务含义的列都有改变的可能性,主键一旦带上了业务含义,那么主键就有可能发生变更。主键一旦发生变更,该数据在磁盘上的存储位置就会发生变更,有可能会引发页分裂,产生空间碎片。
还有就是,带有业务含义的主键,不一定是顺序自增的。那么就会导致数据的插入顺序,并不能保证后面插入数据的主键一定比前面的数据大。如果出现了,后面插入数据的主键比前面的小,就有可能引发页分裂,产生空间碎片。
5:货币字段用什么类型?
货币字段一般都用 Decimal类型,
float和double是以二进制存储的,数据大的时候,可能存在误差。看下面这个图就明白了:
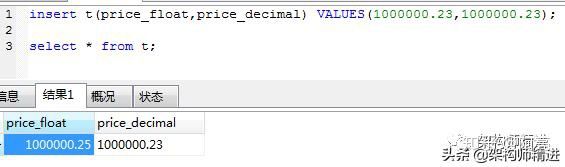
6:时间字段用什么类型?
这个看具体情况和实际场景,timestamp ,datatime ,bigint 都行!
timestamp,该类型是四个字节的整数,它能表示的时间范围为1970-01-01 08:00:01到2038-01-19 11:14:07。2038年以后的时间,是无法用timestamp类型存储的。
但是它有一个优势,timestamp类型是带有时区信息的。一旦你系统中的时区发生改变,例如你修改了时区,该字段的值会自动变更。这个特性用来做一些国际化大项目,跨时区的应用时,特别注意!
datetime,占用8个字节,它存储的时间范围为1000-01-01 00:00:00 ~ 9999-12-31 23:59:59。显然,存储时间范围更大。但是它坑的地方在于,它存储的是时间绝对值,不带有时区信息。如果你改变数据库的时区,该项的值不会自己发生变更!
bigint,也是8个字节,自己维护一个时间戳,查询效率高,不过数据写入,显示都需要做转换。这种存储方式的具有 Timestamp 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
7:为什么不直接存储图片、音频、视频等大容量内容?
我们在实际应用中,都是文件形式存储的。mysql中,只存文件的存放路径。虽然mysql中blob类型可以用来存放大容量文件,但是,我们在生产中,基本不用!
主要有如下几个原因:
1. Mysql内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,查询效率会非常慢。
2. 数据库特别大,内存占用高,维护也比较麻烦。
3. binlog太大,如果是主从同步的架构,会导致主从同步效率问题!
因此,不推荐使用blob等类型!
8:表中有大字段X(例如:text类型),且字段X不会经常更新,以读为主,那么是拆成子表好?还是放一起好?
其实各有利弊,拆开带来的问题:连接消耗;不拆可能带来的问题:查询性能,所以要看你的实际情况,如果表数据量比较大,最好还是拆开为好。这样查询速度更快。
9:字段为什么要定义为NOT NULL?
一般情况,都会设置一个默认值,不会出现字段里面有null,又有空的情况。主要有以下几个原因:
1. 索引性能不好,Mysql难以优化引用可空列查询,它会使索引、索引统计和值更加复杂。可空列需要更多的存储空间,还需要mysql内部进行特殊处理。可空列被索引后,每条记录都需要一个额外的字节,还能导致MYisam 中固定大小的索引变成可变大小的索引。
2. 如果某列存在null的情况,可能导致count() 等函数执行不对的情况。看一下2个图就明白了:
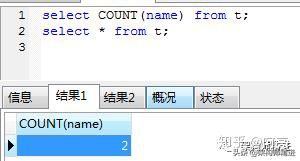
3. sql 语句写着也麻烦,既要判断是否为空,又要判断是否为null等。
二、数据库查询优化
10:where执行顺序是怎样的?
where 条件从左往右执行的,在数据量小的时候不用考虑,但数据量多的时候要考虑条件的先后顺序,此时应遵守一个原则:排除越多的条件放在第一个。
11:应该在这些列上创建索引:
在经常需要搜索的列上,可以加快搜索的速度;在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
12:mysql联合索引
联合索引是两个或更多个列上的索引。对于联合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部分,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a 、 a,b 、 a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引 不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知 道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
13:什么是最左前缀原则?
最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。如下:
select * from user where name=xx and city=xx ; //可以命中索引 select * from user where name=xx ; // 可以命中索引 select * from user where city=xx ; // 无法命中索引
这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如 city= xx and name =xx,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
14:什么情况下应不建或少建索引
表记录太少
经常插入、删除、修改的表
数据重复且分布平均的表字段,假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
经常和主字段一块查询但主字段索引值比较多的表字段
15:问了下MySQL数据库cpu飙升到100%的话他怎么处理?
1. 列出所有进程 show processlist 观察所有进程 多秒没有状态变化的(干掉)
2. 查看慢查询,找出执行时间长的sql;explain分析sql是否走索引,sql优化;
3. 检查其他子系统是否正常,是否缓存失效引起,需要查看buffer命中率;
16、mysql中表锁和行锁的区别
Mysql有很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁;这些锁统称为悲观锁(Pessimistic Lock)
行锁
特点:锁的粒度小,发生锁冲突的概率低、处理并发的能力强;开销大、加锁慢、会出现死锁
加锁的方式:自动加锁。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁;对于普通SELECT语句,InnoDB不会加任何锁。
表锁
特点:开销小、加锁快、无死锁;锁粒度大,发生锁冲突的概率高,高并发下性能低
加锁的方式:自动加锁。查询操作(SELECT),会自动给涉及的所有表加读锁,更新操作(UPDATE、DELETE、INSERT),会自动给涉及的表加写锁。
17、mysql主键索引和普通索引之间的区别是什么
普通索引
普通索引是最基本的索引类型,而且它没有唯一性之类的限制。普通索引可以通过以下几种方式创建:
创建索引,例如
CREATEINDEX<索引的名字>ONtablename (列的列表);
修改表,例如
ALTERTABLEtablenameADDINDEX[索引的名字] (列的列表);
创建表的时候指定索引,例如
CREATETABLEtablename ( [...],INDEX[索引的名字] (列的列表) );
主键索引
主键是一种唯一性索引,但它必须指定为“PRIMARY KEY”。
主键一般在创建表的时候指定,例如
CREATETABLEtablename ( [...],PRIMARYKEY(列的列表) );
但是,我们也可以通过修改表的方式加入主键,例如“ALTER TABLE tablename ADD PRIMARY KEY (列的列表); ”。每个表只能有一个主键。
区别
普通索引是最基本的索引类型,没有任何限制,值可以为空,仅加速查询。普通索引是可以重复的,一个表中可以有多个普通索引。
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值;索引列的所有值都只能出现一次,即必须唯一。简单来说:主键索引是加速查询 + 列值唯一(不可以有null)+ 表中只有一个。
18、SQL JOIN 中 on 与 where 的区别
left join : 左连接,返回左表中所有的记录以及右表中连接字段相等的记录。
right join : 右连接,返回右表中所有的记录以及左表中连接字段相等的记录。
inner join : 内连接,又叫等值连接,只返回两个表中连接字段相等的行。
full join : 外连接,返回两个表中的行:left join + right join。
cross join : 结果是笛卡尔积,就是第一个表的行数乘以第二个表的行数。
关键字 on
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
在使用 left jion 时,on 和 where 条件的区别如下:
1、 on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。
2、where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
假设有两张表:
表1:tab2
idsize110220330
表2:tab2
sizename10AAA20BBB20CCC
两条 SQL:
select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name='AAA'
select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name='AAA')
第一条SQL的过程:
1、中间表
on条件:
tab1.size = tab2.sizetab1.idtab1.sizetab2.sizetab2.name11010AAA22020BBB22020CCC330(null)(null)
2、再对中间表过滤
where 条件:
tab2.name='AAA'tab1.idtab1.sizetab2.sizetab2.name11010AAA
第二条SQL的过程:
1、中间表
on条件:
tab1.size = tab2.size and tab2.name='AAA'
(条件不为真也会返回左表中的记录)tab1.idtab1.sizetab2.sizetab2.name11010AAA220(null)(null)330(null)(null)
其实以上结果的关键原因就是 left join、right join、full join 的特殊性,不管 on 上的条件是否为真都会返回 left 或 right 表中的记录,full 则具有 left 和 right 的特性的并集。 而 inner jion没这个特殊性,则条件放在 on 中和 where 中,返回的结果集是相同的。
19、优化 MYSQL 数据库的方法
(1) 选取最适用的字段属性,尽可能减少定义字段长度,尽量把字段设置 NOT NULL, 例如’省份,性别’, 最好设置为 ENUM
(2) 使用连接(JOIN)来代替子查询:
(3) 使用联合 (UNION) 来代替手动创建的临时表
(4) 事务处理:
(5) 锁定表,优化事务处理:
(6) 使用外键,优化锁定表
(7) 建立索引
(8) 优化 sql 语句
20、适用MySQL 5.0以上版本:
1.一个汉字占多少长度与编码有关: UTF-8:一个汉字=3个字节 GBK:一个汉字=2个字节
21、php读取文件内容的几种方法和函数?
打开文件,然后读取。Fopen() fread()
打开读取一次完成 file_get_contents()
https://zhuanlan.zhihu.com/p/116866170

最新评论: