一、背景
Elasticsearch是最近几年非常热门的分布式搜索和数据分析引擎,携程内部不仅使用ES实现了大规模的日志平台,也广泛使用ES实现了各个业务场景的搜索、推荐等功能。本文聚焦在业务搜索的场景分享了我们在做数据同步方面的思考和实践,希望能对大家有所启发。数据同步是个很麻烦的事情,在各种论坛、分享中被大家反复讨论。我们的需求大致包括全量、增量地从Hive、MySql、Soa服务、Mq等不同类型的数据源获取数据,部分数据还需要进行一定的计算或者转换,然后近实时地同步到ES中,以被用户搜索到。1)索引内容为文章,主要的信息保存在article表里;2)每个文章关联了tag,保存在article_tag表里;3)tag表里的tagName也需要进入ES索引,以便使用标签名字搜索文章;在以前同步这样的数据进入ES,单条文章的数据组装伪代码如下:List<Long> tagIds = articleTagDao.query("select tagId from article_tags where articleId=?", articleId);
List<TagPojo> tags =tagDao.query("select id, name from tags whereid in (?)");
ArticleInEs articleInEs = new ArticleInEs();
articleInEs.setTagIds(tagIds);
articleInEs.setTagNames(tags.stream().filter(tag-> tagIds.contains(tag.getId())).map(TagPojo::getName).collect(Collectors.toList()));
只是一个标签的信息的组装代码就如此繁琐,而实际的情况要复杂得多。比如可能会有十几个乃至几十个ES索引字段,或者还要考虑代码、SQL性能以及业务逻辑,组装数据这个工作本身就已经让人头秃了,更别说可能还有业务的逻辑要处理了。由于携程使用ES的业务非常多,迫切需要一个简单易用的框架或者工具完成这个工作,以便大家从繁琐重复的代码里脱身,专注在完成业务本身上。开源社区有很多类似的实现,类似elasticsearch-jdbc、go-mysql-elasticsearch、Logstash等,经过评估我们认为存在以下问题,无法落地:1)常见的工具都是基于配置的,固然非常方便,但是由于安全的原因,我们拿不到生产环境的DB的明文连接串,无法配置数据源;2)从DB得到的数据有时候需要经过处理以后才能推送给ES,简单的基于配置的方式无法满足;3)ES的用户名、密码等,我们不希望出现在配置中,需要有统一的地方对连接信息进行管理,以保证安全及便于维护;4)数据的组装有的场景比较复杂,目前这些工具的配置写起来可能比代码还繁琐;5)增量的数据来源,有时候是MQ,无法使用配置进行更新;6)有的工具是单独的命令行,无法和我们的JOB结合(基于JAVA)评估下来,发现这几个工具更适用于简单的DB数据,或者已经有了DB平表的场景。一则我们场景有比较复杂的,一则有平表的话同步到ES已经不是多麻烦的事情了。我们需要造一个车轮才能解决全部需求,除了满足以上提到的开源工具不支持的场景,还要保留他们的基于配置的机制,达到只完成必要的SQL、ES Mapping,和增加必要的数据源即可完成索引的创建工作。
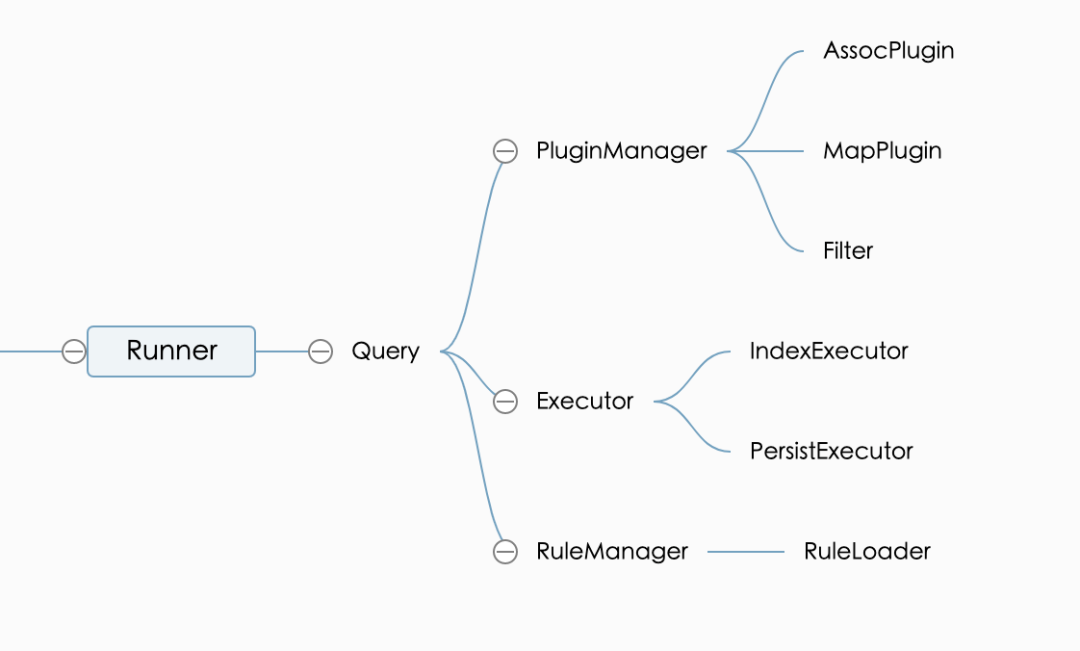
1)第一种是全量同步,全量由于是对整个索引的变更,所以既要保证稳定,又要确保不会创建有问题的索引。全量会从零创建一个全新的索引。同步开始前,会修改索引mapping的number_of_replicas为0、refresh_interval为-1等参数,以提高索引速度。同时增加了一个_indexTime的字段,表示本数据的更新时间,用于后续的查错、比对等;索引全部完成以后,增加了force merge、恢复mapping修改、_refresh等操作,保证建立的索引是尽可能紧凑的;通过定时确保索引的health索引是绿色的,以免未完全准备好切换后耗时不稳定;最后检查本次索引最终的有效文档数和线上有效索引的文档数的差值是否在配置的可接受范围内,如果不在则认为本次索引出错,删除本次索引内容。2)第二种是MQ增量,携程内部使用QMQ接收了来自Otter的MySql变更,MQ里会有变化的数据库表、字段的信息,因此可以针对性地实现对MQ的解析的规则,从而可以轻而易举地达到通过MQ对ES里的文档进行全部、部分的索引。由于大部分情况MQ里的信息都比较少,因此更多的情况下,建议收到MQ以后,采用第三种方法进行增量。3)第三种是Id增量,由使用方传入需要索引的Id列表,使用Id根据配置生成完整的文档提交到ES,以简化整个索引过程的模型。这种方法是最常用的,对临时更新数据也非常友好。如果提供的Id在最终的数据里没有发现,将删除ES里对应的数据,以处理数据在DB里被物理删除的情况。4)最后一种是时间增量,组件会维护每个索引的更新时间,以确保增量JOB滚动执行的时候,新的数据总是能尽快地进入ES。由于该方案会要求定期查指定表里的最新数据,因此对DB不是很友好,大部分情况下我们并不是很建议使用该方法维护索引。以上几种场景,全量、Id和时间增量,都要求配置能拼装出完整的文档,确保每次发送给ES的都是完整的文档。实现上需要确保建立全量的过程里发生的增量,在新建的索引切换到线上使用之前,能够同步到增量,这一步通常是在MQ里进行处理。1)基于SQL的配置,完成类似文章标签的关联,这种组装场景非常简单,有时候也是为了简化SQL或者优化SQL性能,而单独拎出来的查询;由于逻辑的通用型,因此内置了代码插件实现该类型数据的读取和组装。2)基于代码的处理,适用于类似SQL不方便完成、需要从SOA服务查询数据,或者数据需要进行复杂处理的场景;这种需要使用自己根据组件的要求实现自定义插件,以提供数据给组件进行统一处理。1)Runner,是组件的调用总入口,负责参数的解析、Executor的生成、Rule等模块的初始化等。借助封装的友好型,Runner可以配合分布式JOB完成同一索引的并行建立,以加快整个索引的建立速度,这种并行方式在内部已经广泛使用。2)Query,是整个内部流程的控制中心,负责根据Runner传入的参数,进行SQL的拼装、DB的读取、Executor和Plugin的调度等。不同的索引方式,需要对SQL进行不同的预处理,类似时间增量需要维护增量的时间等,也在该模块内完成。为了简化开发成本,Query里也实现了执行配置里指定的Groovy脚本,在数据进入Executor前可以在脚本中进行处理,某些简单的场景里可以非常轻便地实现数据过滤和处理。3)PluginManager,负责插件配置的解析、插件实例的生成、插件的调用管理等。我们归纳了常见的数据组装的方式,提供了几个内置的插件,基本上就能完成大部分基于DB的数据获取和组装。比如Assoc Plugin可以完成类似文章标签这种聚合场景,Map Plugin可以完成类似Map的映射场景,而Filter则支持对每一条数据进行简单的过滤处理,类似去Html、去重等。为了减少对DB的压力,内置的插件都支持设置数据的缓存时间,有效时间内,优先取内存里保存的数据。4)Executor,用于接收来自Query的数据,完成真正落地动作。内置了两种Executor,使用方可以按照具体情况选择:
5)RuleManager/Rule Loader,用于完成规则的加载和管理,支持从公司统一的QConfig或者当前工程的资源文件夹读取配置。插件实现了像ES一样的检测,对不符规范的配置会提供相应的报错,以减少因配置问题造成的数据错误。
实际工作中,还有Hive到ES等场景,由于不在本组件范围内,因此文中没有讨论。目前我们也有场景是使用ES-Hadoop完成全量索引建立以后,使用本组件维护增量的。目前已经有数个业务几十个索引使用了该组件维护索引,让研发人员最大程度的关注在业务逻辑上,而不被繁琐的重复代码所干扰。通过该组件,可以将不同数据源的数据,通过组装导出到ES索引中,也能导出到DB平表中,因此在部分数据同步的场景里也可以使用。
https://mp.weixin.qq.com/s/2PRX_vVhi3SygrZydBfG6w

最新评论: