文章目录
上篇从日常代码出发,着重讨论了Java、MySQL等应用层中日期时间的表示和存储等操作、可能遇到的坑,及时区转换相关方法。下篇将尽量深入底层,看看我们在用及“日期时间”时,计算机中发生了什么。
1. 奇怪的现象
上篇中讲过 System.currentTimeMillis() 的用法,也提到了高频调用时会产生一定性能问题,我们先来看现象:
用以下代码大致测量 System.currentTimeMillis() 方法的执行速度(运行一亿次,求平均时间):
long sum = 0L;
int N = 100000000;
long begin = System.currentTimeMillis();
for (int i = 0; i < N; i++) {
sum += System.currentTimeMillis();
}
long end = System.currentTimeMillis();
System.out.println("sum = " + sum + "ms");
System.out.println("total time = " + (end - begin) + "ms");
System.out.println("average time = " + (end - begin) * 1.0E6 / N + " ns/iter");查看不同系统的输出如图所示:
Windows(Windows 10,Intel® Core™ i5-6500):
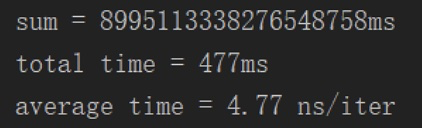
macOS(macOS High Sierra,2.3 GHz Intel Core i5,MacBook Pro 2017):
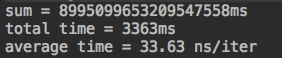
Linux(3.10.0-327.28.3.el7.x86_64,Intel® Xeon® CPU E5-2620 v3 @ 2.40GHz,服务器实体机):
默认TSC时间源

切换为另外一常用时间源:HPET

梳理以上实验:
| 操作系统类型 | 平均执行时间(ns/次) |
|---|---|
| Windows | 4.77 |
| macOS | 33.63 |
| Linux(TSC) | 27.43 |
| Linux(HPET) | 574.93 |
结果是没有预料到的,最快和最慢差异能达到两个数量级,原因我们下面细细道来。
2. 深入探索 System.currentTimeMillis()
System.currentTimeMillis() 是一个 native 方法,它的代码可以参考OpenJDK,我们找出此方法的JVM实现如下 hotspot/src/share/vm/prims/jvm.cpp :
JVM_LEAF(jlong, JVM_CurrentTimeMillis(JNIEnv *env, jclass ignored))
JVMWrapper("JVM_CurrentTimeMillis");
return os::javaTimeMillis();
JVM_END调用了 os::javaTimeMillis() 方法,不同系统有不同的实现。Mac和Linux(TSC)的执行时间相近,我们挑选Windows和Linux系统探究原理并比较。
2.1. Windows实现
在 hotspot/src/os/windows/vm/os_windows.cpp 中追踪其实现如下:
jlong os::javaTimeMillis() {
if (UseFakeTimers) {
return fake_time++;
} else {
FILETIME wt;
GetSystemTimeAsFileTime(&wt);
return windows_to_java_time(wt);
}
}
jlong windows_to_java_time(FILETIME wt) {
jlong a = jlong_from(wt.dwHighDateTime, wt.dwLowDateTime);
return (a - offset()) / 10000;
}
jlong offset() {
return _offset;
}
static jlong _offset = 116444736000000000;由此可见该方法关口在于Windows的 GetSystemTimeAsFileTime() 方法,在Microsoft开发网站上(Docs/Windows/Sysinfoapi.h/GetSystemTimeAsFileTime function)说明为:
该方法返回一个 FILETIME 类型的数据,其中包含两个32位字段:dwLowDateTime 和 dwHighDateTime,分别代表当前 FILETIME 的低位和高位。组合起来返回1601年1月1日(UTC)以来以100ns为间隔的数量,减去 116444736000000000(1601年1月1日至1970年1月1日的100纳秒间隔个数)再除以 10000,即是当前Unix时间戳毫秒数。
为什么是1601年?
因为现行 Gregorian Calendar 的时间周期是400年一轮(四年一闰,百年不闰,四百年再闰),1601年是距离Windows系统开始开发最近的一个400年周期点,把它作为系统时间的起点,那么把NT时间转换为常规日期表达(或相反)就不用做任何跳跃操作。
这个方法是在 kernel32.dll 中实现的,在VC中执行GetSystemTimeAsFileTime(&f)方法,从调试的 disassembly 模式调出执行的汇编语句如下图:
执行的两句语句如下图,会首先去 call 调用 kernel32.dll 中的方法:
然后 jmp 到其具体实现:
关键流程:
执行后的结果,dwHighDateTime 和 dwLowDateTime 两个字段即为取出的数据:
进行转换操作:((dwHighDateTime << 32) + dwLowDateTime - offset) / 10000即可转换为我们熟悉的Unix时间戳: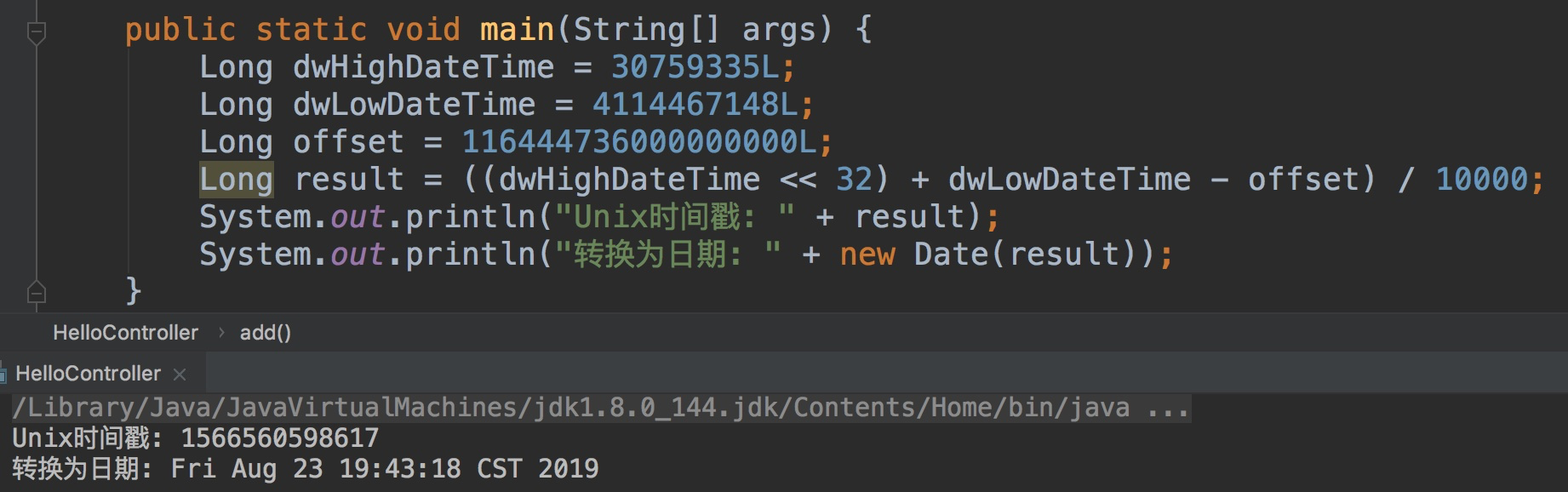
整个流程已经明晰,追踪下来可以了解到:此方法的执行逻辑仅仅是到固定的内存空间取这两个32位字段的值,没有经过任何用户态和内核态的转换过程。有一个后台进程会定期更新此内存空间中的字段值,保证是能取到的最新时间。
但是我们日常使用的Windows都不是实时操作系统(RTOS),系统提供的时间精度并没有到纳秒级别,我们来测试一下实际可以达到的最小时间间隔:
#include <stdio.h>
#include <time.h>
#include <windows.h>
#define N 1000000
int values[N];
int main(void)
{
int i;
for (i = 0; i < N; i++) {
FILETIME f;
GetSystemTimeAsFileTime(&f);
values[i] = (int) f.dwLowDateTime;
}
for (i = 1; i < N; i++)
if (values[i-1] != values[i])
printf("%d %d\n", i, values[i] - values[i-1]);
return 0;
}以上代码调用 1,000,000 次 GetSystemTimeAsFileTime 方法,并将得到的时间放到一个数组中,然后找出相邻两位不同的数字并求差,就是可以测算出的最小时间间隔。实验结果如下: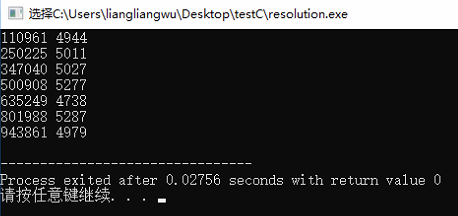
可以看到平均最小时间间隔为5000个100ns,即0.5毫秒,远没有达到ns级,但是已经够 System.currentTimeMillis() 的精度要求了。
综上,Windows系统下的 System.currentTimeMillis() 执行速度极快,约为4.77ns,最小时间间隔约为0.5毫秒。
2.2. Linux实现
在 hotspot/src/os/linux/vm/os_linux.cpp 中追踪其实现如下:
jlong os::javaTimeMillis() {
timeval time;
int status = gettimeofday(&time, NULL);
assert(status != -1, "linux error");
return jlong(time.tv_sec) * 1000 + jlong(time.tv_usec / 1000);
}乘除法的时间消耗不会到百纳秒级别,可见该方法的关口在于 gettimeofday() 方法。接下来让我们一步一步深入Linux源码探个究竟。
首先要明确实验机器的环境,如下图:
在 linux/v3.10/source/arch/x86/vdso/vclock_gettime.c 中找到 gettimeofday 方法:
int gettimeofday(struct timeval *, struct timezone *)
__attribute__((weak, alias("__vdso_gettimeofday")));可以看到,这里使用了vDSO(virtual dynamic shared object,直译为虚拟动态共享对象)。
关于 vsyscall 和 vDSO,内容着实精彩,但不是本文重点,感兴趣的同学可以参考 System calls in the Linux kernel. Part 3. 等。
继续查看 __vdso_gettimeofday() 方法(部分):
notrace int __vdso_gettimeofday(struct timeval *tv, struct timezone *tz)
{
long ret = VCLOCK_NONE;
if (likely(tv != NULL)) {
// 实际获取时钟源时间的方法
ret = do_realtime((struct timespec *)tv);
tv->tv_usec /= 1000;
}
// 如果通过虚拟系统调用未获取到,则执行真正的系统调用,陷入内核态获取时间
if (ret == VCLOCK_NONE)
return vdso_fallback_gtod(tv, tz);
return 0;
}可以看到,其中主流程调用了 do_realtime() 方法获得当前机器时间,do_realtime 方法源码如下:
#define gtod (&VVAR(vsyscall_gtod_data))
notrace static int __always_inline do_realtime(struct timespec *ts)
{
unsigned long seq;
u64 ns;
int mode;
ts->tv_nsec = 0;
do {
seq = read_seqcount_begin(>od->seq);
mode = gtod->clock.vclock_mode;
ts->tv_sec = gtod->wall_time_sec;
ns = gtod->wall_time_snsec;
ns += vgetsns(&mode);
ns >>= gtod->clock.shift;
} while (unlikely(read_seqcount_retry(>od->seq, seq)));
timespec_add_ns(ts, ns);
return mode;
}上述源码中可以看出,虚拟内存调用的逻辑和Windows中的逻辑很相近,都是从一个地址空间(上述源码通过变量gtod寻址)上定义好的数据结构中读取出当前机器时间。同时,一些后台线程会定期更新此结构的字段。
值得注意的是,Windows中两次读取高位数字并比较来确保读取的多个值的顺序一致性,这点在Linux中通过内存屏障来保证,这便是 read_seqcount_begin 和 read_seqcount_retry 的作用。同时,Intel x86的强内存排序也可以做到这一点。若有兴趣的同学可以详细了解源码及系统实现方法。
当前机器时间由两个字段表示:wall_time_sec 和 wall_time_snsec。wall_time_sec 代表机器从机器计时起点开始经过的秒数,wall_time_snsec 代表相对于最后一秒经过的纳秒级别时间,其精度可以通过 gtod->clock.shift 控制。参考了一些文献中的实验,现有 wall_time_snsec 的精度一般可以达到一毫秒以内。
至此,只是从固定地址空间读取和计算,并不会耗费很多时间。然而Linux并不满足于直接读取出的时间数值,试图继续通过 vgetsns() 方法获取更高精度的时间。vgetsns() 方法源码如下:
notrace static inline u64 vgetsns(int *mode)
{
long v;
cycles_t cycles;
if (gtod->clock.vclock_mode == VCLOCK_TSC)
cycles = vread_tsc();
else if (gtod->clock.vclock_mode == VCLOCK_HPET)
cycles = vread_hpet();
else if (gtod->clock.vclock_mode == VCLOCK_PVCLOCK)
cycles = vread_pvclock(mode);
else
return 0;
v = (cycles - gtod->clock.cycle_last) & gtod->clock.mask;
return v * gtod->clock.mult;
}至此我们终于见到了文章开篇问题中提到的时间源问题!系统中存在几个高频计时器,vgetsns() 方法会根据当前系统指定的计时器种类去读取该计时器中的“cycles”,即经过了多少个高频时钟周期,然后通过 gtod-> mask 和 gtod-> mult 字段进行时间的转换,并加到 wall_time_snsec 代表的纳秒时间数值中。
由文章开篇的现象可知,不同时间源获取时间的代价不同,追踪至此我们可以得出,就是在 vgetsns() 方法中消耗的时间成本导致的,而不同时间源的获取成本不同,则是由于其硬件构造和发展。
至此,可以说是部分“破案”了,之所以不同系统不同时间源差异如此之大,是由于实现方式不同。Windows平台只是到固定的内存空间取两个32位字段的值并进行计算,所以最快;Linux中在此基础上通过读取高频计时器来提高获取的时间精度,所以普遍稍慢;也就是在这一步骤中,不同计时器的读取代价不同,造成总的执行成本有巨大差异。
说了这么久时间源的问题,但还没有了解时间源的相关概念,下面我们详细介绍。
3. 常见的时钟、定时器硬件和时间源概念
不论软件层面如何读取如何计算,时间点的获取和时间段的计量总是要通过硬件来完成的。本章主要介绍几种常见的时钟和定时器硬件,及Linux在硬件上层抽象出的“时间源”数据结构。
3.1. 常见时钟和定时器硬件
3.1.1. 实时时钟(RTC)
和其他时钟硬件不同,实时时钟RTC(Real Time Clock)输出的是UTC时刻,而其他硬件如TSC、PIT、HPET等输出的都只是周期数,即“我已经走过XXX个cycle了,我的频率是XXX,你自己去算吧!”
这是因为RTC是独立于CPU和其他所有芯片的,即使当PC电源被切断RTC还可以继续工作。RTC和 CMOS RAM 被集成在一个芯片(Motorola 146818或其他等价的芯片)上,它靠主板上的一个小电池或蓄电池独立供电。
当然,既然RTC已经如此独特,它输出的时间精度自然不会很高(秒级),不然也没别的硬件什么事儿了。它可以在IRQ8上发出周期性的中断,主要用于在系统启动初始化时不依靠网络等外界帮助获取当前时间等,剩下的高精度需求就交给其他时间源来做。
3.1.2. 时间戳计数器(TSC)
所有的 80x86 微处理器都包含一条CLK输入引线,它接收外部振荡器的时钟信号,从CLK管脚输入,以提供执行指令所需时钟沿。80x86 提供了一个 TSC 寄存器,该寄存器的值在每次收到一个时钟信号时加一。比如 CPU 的主频为 1GHZ,则每一秒时间内,TSC 寄存器的值将增加 1G 次,或者说每一个纳秒加一次。x86 还提供了 rtdsc 指令来读取该值,因此 TSC 也可以作为时钟设备。要注意,当使用这个寄存器时,必须考虑到时钟信号的频率。
3.1.3. 可编程间隔定时器(PIT)
可编程间隔定时器PIT(Programmable Interval Timer)以内核确定的固定频率不停地发出时钟中断,类似于“打拍子”。由于PIT出现较早,时钟频率也不高,渐渐被更加精确的HPET所取代,在此不过多介绍。
3.1.4. 高精度事件定时器(HPET)
HPET是由微软和英特尔联合开发的定时器芯片,用以取代PIT提供高精度的时钟中断(10MHz以上)。一个HPET芯片包含了8个32位或64位的独立计数器,每个计数器由自己的时钟信号驱动,每个计时器又包含了一个比较器和一个寄存器(保存一个数值,表示触发中断的时机)。每一个比较器都比较计数器中的数值和寄存器的数值,相等就会产生中断。
3.1.5. 其他定时器硬件
其他定时器硬件还包括:CPU本地定时器、ACPI电源管理定时器等。他们处于不同的位置,也有不同的时钟频率,但是由于综合功能和性能不及TSC和HPET,多数系统并未以其作为 current_clocksource。
3.2. clocksource数据结构
上文讲了众多的时间相关硬件,Linux为了管理这些硬件,抽象出来clocksource数据结构。
查看实验机器可用的clocksource,包括:tsc、hpet、acpi_pm:
在 linux/v3.10/source/include/linux/clocksource.h#L166 中可以找到clocksource数据结构的定义:
struct clocksource {
/*
* Hotpath data, fits in a single cache line when the
* clocksource itself is cacheline aligned.
*/
cycle_t (*read)(struct clocksource *cs);
cycle_t cycle_last;
cycle_t mask;
u32 mult;
u32 shift;
u64 max_idle_ns;
u32 maxadj;
#ifdef CONFIG_ARCH_CLOCKSOURCE_DATA
struct arch_clocksource_data archdata;
#endif
const char *name;
struct list_head list;
int rating;
int (*enable)(struct clocksource *cs);
void (*disable)(struct clocksource *cs);
unsigned long flags;
void (*suspend)(struct clocksource *cs);
void (*resume)(struct clocksource *cs);
/* private: */
#ifdef CONFIG_CLOCKSOURCE_WATCHDOG
/* Watchdog related data, used by the framework */
struct list_head wd_list;
cycle_t cs_last;
cycle_t wd_last;
#endif
} ____cacheline_aligned;此数据结构中定义了很多时间源相关参数,比较重要的是 rating、shift、mult。
3.2.1. rating
精度越高的时间源,频率越高,rating值越大。从该源码的注释中可以得知:
1–99: 不适合于用作实际的时钟源,只用于启动过程或用于测试;
100–199:基本可用,可用作真实的时钟源,但不推荐;
200–299:精度较好,可用作真实的时钟源;
300–399:很好,精确的时钟源;
400–499:理想的时钟源,如有可能就必须选择它作为时钟源;
linux/v3.10/source/drivers/clocksource/acpi_pm.c#L66中显示,ACPI时间源的rating是200;
linux/v3.10/source/arch/x86/kernel/hpet.c#L748 中显示,HPET时间源的rating是250;linux/v3.10/source/arch/x86/kernel/tsc.c#L775 中显示,TSC时间源的rating是300。
对应的,时间源硬件的频率查看如下: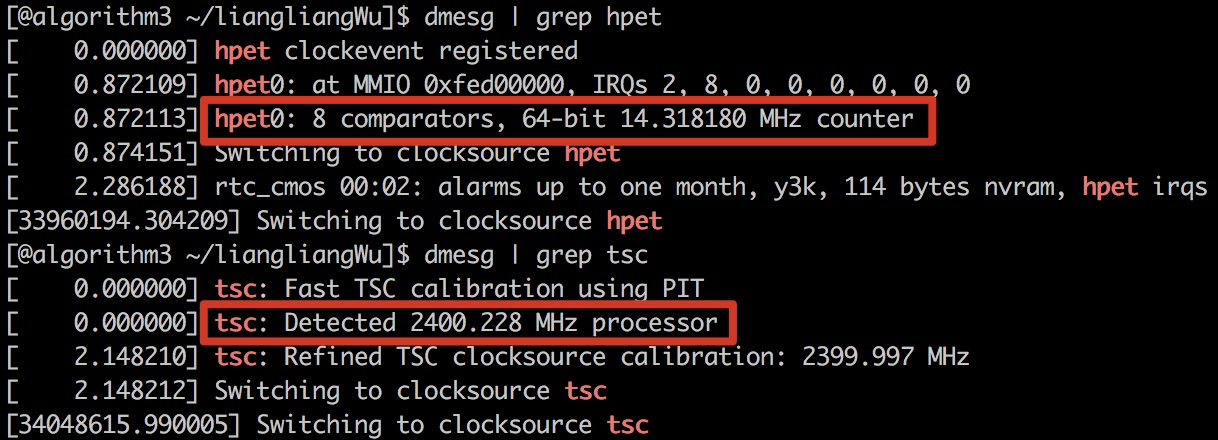
可见,TSC时间源简直“超凡脱俗”。
3.2.2. shift 和 mult
由于除RTC外的硬件输出都是“节拍数”,所以要根据硬件频率换算成具体的时间段,公式为:时间段 = 节拍数 / 频率。其中,节拍数可以通过 clocksource 数据结构中的成员变量 read 所指向的函数获取。例如 clocksource_tsc 的定义中深挖到最后是通过 rdtsc 指令来获取当前计数值cycles的。
可是这些和shift、mult两个变量有什么关系呢?计算机中对于除法的计算转化为乘法和移位更加方便,公式就变成了:时间段 = 节拍数 * mult >> shift。在 linux/v3.10/source/include/linux/clocksource.h#L275 中 定义如下:
static inline s64 clocksource_cyc2ns(cycle_t cycles, u32 mult, u32 shift)
{
return ((u64) cycles * mult) >> shift;
}3.3. 不同时间源的比较
3.3.1. 如何比较
由于有上述好多种时间源,不可避免要比较各个功能性能优劣,并将它们放在最合适的位置。比较的维度有多种:
从功能上说,RTC时间源有自己独特的
直接返回UTC时刻且“不断电”的能力,虽然只能精确到秒级,但是足以应对系统时间初始化等场景。从性能上讲,比如上文已经提到的MHz为单位的时钟频率,部分反映在clocksource数据结构中的rating字段,是重要的衡量标准,决定了时间到底能精确到什么程度,CPU中的时间精度也就决定了计算速度的上限(时钟沿变化)。
还有一些其他要注意的点。比如TSC代表时间戳记计数器,它仅仅是自启动以来计算的CPU周期数。曾经在很长一段时间里,这个值有两个问题:来自不同内核或物理处理器的值可能相互不统一,因为处理器可能在不同的时间开始启动;处理器的时钟频率可能会在执行期间发生变化,给计算实际流逝时间段造成困难。但是这些问题随着处理器不断更新换代进行了修复与升级,具体有兴趣的同学可以参考Intel等的官方文档。
整体来讲,系统的默认时间源是在根据硬件发展不停变化的,现在大多数默认时间源是TSC,在2007版的《深入理解Linux内核》一书中,当时最优的时间源还是HPET:
所以,大家要尽量在稳定基础理论的前提下,具体实操时了解确认最新的技术。
针对现有的硬件,还要给大家提醒一个可能遇到的“坑”:多线程使用问题。
3.3.2. 不同时间源的多线程使用的“坑”
文章开头已经给出,在Linux环境下,TSC和HPET的执行速度大概是 27.43 ns/次 和 574.93 ns/次 。这是单线程执行的结果,实际开发中会有很多多线程场景,或一个物理机上有多个程序在跑,那么他们会互相有影响吗?
3.3.2.1 现象
我们通过实验来验证。测试代码如下:
public class Time {
static double sumAvg = 0;
public static void main(String[] args) throws InterruptedException {
// 测试机器24核,所以以24为上限进行测试,
for (int threadNums = 1; threadNums <= 24; threadNums++) {
// 各线程平均时间的累加,用于最后计算平均时间的平均数(可能中文表述难以理解,看代码吧)
sumAvg = 0;
// 控制主线程在子线程执行之后再进行平均值计算
final CountDownLatch countDownLatch = new CountDownLatch(threadNums);
for (int i = 0; i < threadNums; i++) {
// 每个线程测试平均每次 System.currentTimeMillis() 的请求时间
new Thread(() -> {
int N = 10000000;
long begin = System.currentTimeMillis();
for (int j = 0; j < N; j++) {
System.currentTimeMillis();
}
long end = System.currentTimeMillis();
double thisAvg = (end - begin) * 1.0E6 / N;
sumAvg += thisAvg;
countDownLatch.countDown();
}).start();
}
countDownLatch.await();
System.out.println("thread numbers = " + threadNums + ", average time = " + sumAvg / threadNums + " ns/iter");
}
}
}使用TSC时间源

Excel图表表示更为清晰: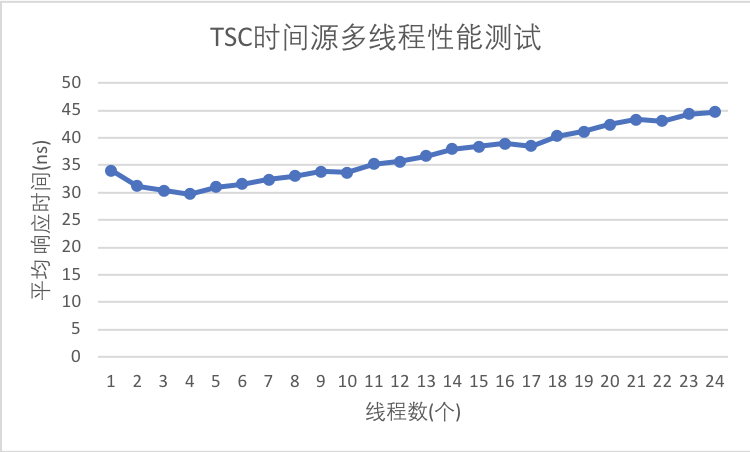
忽略double的丢失精度,可以看出:随着线程数增加,单个请求的耗时变化并不算大,只有在线程数接近核数时才些许上升。使用HPET时间源
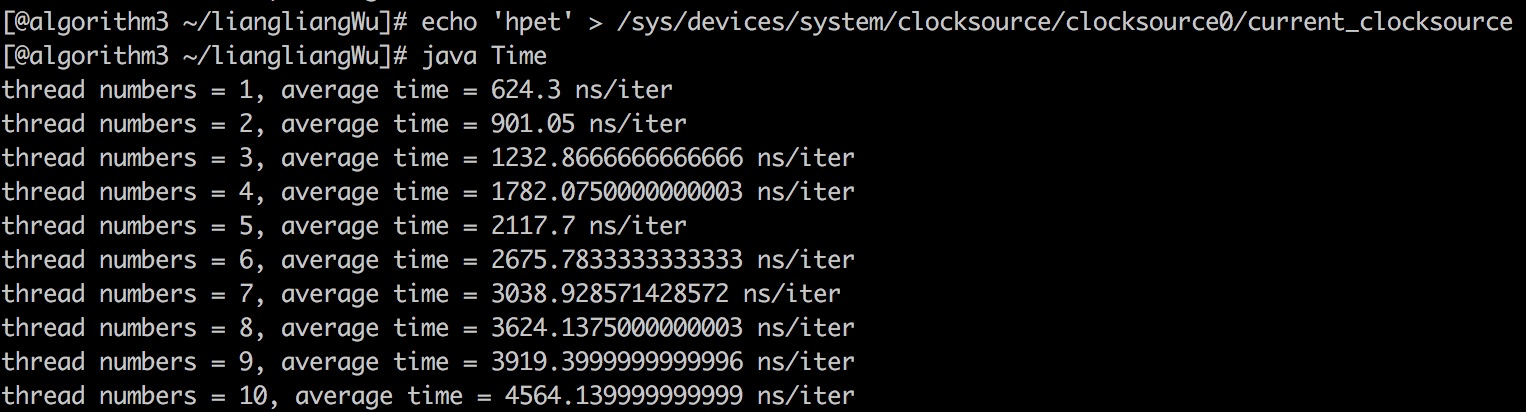
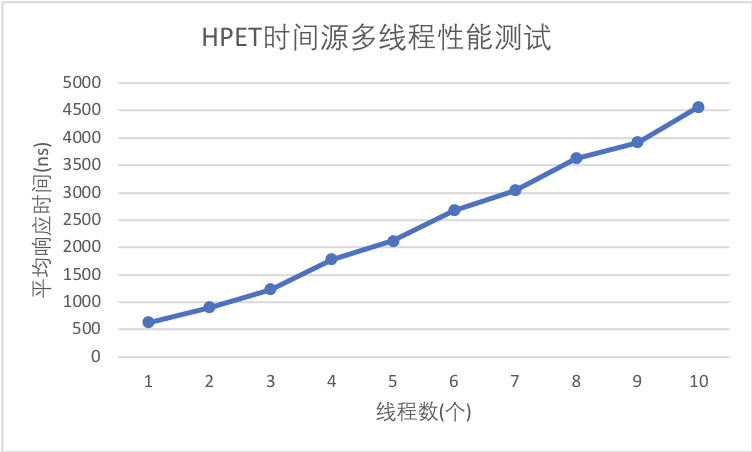
在10个线程的时候已经达到了 44564ns/iter ,为了不影响服务没有继续增加线程数。但是趋势已经非常明显:随着线程数增加,单个请求的耗时呈线性增长。合理猜想,HPET时间源可能会串行化请求,或是有某个或多个步骤是处于临界区的,导致多个线程之间的相互影响,性能线性下降。至于理论依据还有待从硬件的角度考察。可能造成的问题
由于处理器在使用HPET时会相互影响,因此存在潜在的安全问题。一个进程可能会执行紧密循环调用 gettimeofday() 方法,从而导致所有其他进程调用此方法时性能降低。况且本来HPET的时间成本就较高,所以更要谨慎使用。
3.3.2.2 高并发下可用的解决方案
(1)如果并发量高但是对时间精确度要求不高的话可以使用独立线程缓存时间戳。只要用一个变量存当前时间戳,每过固定的一段间隔更新一次,其他调用需求直接取这个变量即可,实现举例如下:
class MillisecondClock {
// 自定义的间隔时间段
private long gap = 0;
// 要缓存的当前时间点
private volatile long now = 0;
private MillisecondClock(long gap) {
this.gap = gap;
this.now = System.currentTimeMillis();
start();
}
private void start() {
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(gap);
} catch (InterruptedException e) {
e.printStackTrace();
}
now = System.currentTimeMillis();
}
}).start();
}
public long now() {
return now;
}
}(2)如果有必要,使用JNI将 System.currentTimeMillis() 方法调用的 gettimeofday() 方法换成 clock_gettime() 方法,会更加高效,详细不再展开;
(3)使用 System.nanoTime() 方法;
至此,系统常用的时钟、定时器硬件及系统为其抽象出的数据结构及其区别简要介绍完毕。
4. Linux计时体系结构
以上文中我们从探究的思路步步深入了 System.currentTimeMillis() 方法是如何获取当前时间点的,以及在时间源的层次考虑不同硬件及其抽象出的数据结构之间的差异。本章将从体系结构的角度,选取博大精深的Linux系统,介绍系统对于时间的管理。
所谓“体系结构”的概念是指一组部件和部件之间的联系,具体到操作系统我们可以理解为定义的数据结构和操作硬件赋能这些数据结构的方法。
Linux对于时间的管理主要还是那两方面:时间点和时间段,即维护系统时间和管理定时器。下面依次介绍,有些上文中提过的将会简略些。
4.1. 系统时间
这里的系统时间就是上文中 gettimeofday() 方法所获取的时间,由于有了 vDSO 不用再进行用户态和内核态的切换,直接读取系统时间。但是这个系统时间是怎么维护的呢?
Linux中定义了一个xtime对象,用来存放当前的时间和日期,它是一个timestamp类型的数据结构,该数据结构在 linux/v3.10/source/include/uapi/linux/time.h#L9 中定义如下:
struct timespec {
__kernel_time_t tv_sec;
long tv_nsec;
};其中的两个变量:
tv_sec 存放自1970年1月1日(UTC)00:00以来经过的秒数
tv_nsec 存放自上一秒开始经过的纳秒数
是不是十分熟悉?下面我们抛开vDSO来介绍系统对于时间的操作。
4.1.1. 系统时间的初始化
内核初始化期间,在 linux/v3.10/source/init/main.c 中调用了timekeeping_init() 方法来初始化“墙上时间”。向下追溯,在 linux/v3.10/source/kernel/time/timekeeping.c#L770 中的 timekeeping_init() 方法 => linux/v3.10/source/arch/x86/kernel/rtc.c#L142 中的 read_persistent_clock() 方法:
void read_persistent_clock(struct timespec *ts)
{
unsigned long retval;
retval = x86_platform.get_wallclock();
ts->tv_sec = retval;
ts->tv_nsec = 0;
}linux/v3.10/source/arch/x86/kernel/rtc.c#L61 中的 get_wallclock() => mach_get_cmos_time() 方法(截取部分):
unsigned long mach_get_cmos_time(void)
{
unsigned int status, year, mon, day, hour, min, sec, century = 0;
unsigned long flags;
spin_lock_irqsave(&rtc_lock, flags);
while ((CMOS_READ(RTC_FREQ_SELECT) & RTC_UIP))
cpu_relax();
sec = CMOS_READ(RTC_SECONDS);
min = CMOS_READ(RTC_MINUTES);
hour = CMOS_READ(RTC_HOURS);
day = CMOS_READ(RTC_DAY_OF_MONTH);
mon = CMOS_READ(RTC_MONTH);
year = CMOS_READ(RTC_YEAR);
return mktime(year, mon, day, hour, min, sec);
}而后 linux/v3.10/source/kernel/time.c#L322 中 mktime() 方法对年月日等进行了转换:
unsigned long mktime(const unsigned int year0, const unsigned int mon0,
const unsigned int day, const unsigned int hour,
const unsigned int min, const unsigned int sec)
{
unsigned int mon = mon0, year = year0;
/* 1..12 -> 11,12,1..10 */
if (0 >= (int) (mon -= 2)) {
mon += 12; /* Puts Feb last since it has leap day */
year -= 1;
}
return ((((unsigned long)
(year/4 - year/100 + year/400 + 367*mon/12 + day) +
year*365 - 719499
)*24 + hour /* now have hours */
)*60 + min /* now have minutes */
)*60 + sec; /* finally seconds */
}可见,系统初始化时会进行时钟初始化,读取RTC时间源上的UTC毫秒时间,赋值给xtime变量的 tv_sec 字段,并将xtime变量的 tv_nsec 字段赋值为0。初始化过程完成。
这样初始化出的系统时间值其实是不精确的,因为并没有地方获取准确的纳秒数。其实计算机会用到NTP等服务进行时间的精确同步,有兴趣的同学可以进一步了解。但是话说回来,不联网的单机用户对于当前绝对时间点的精确度要求其实并没有那么高,给手枪加上狙击镜的意义不大。反而是对于时间段的精确度很高,那留到下一节定时器去介绍吧。
在 linux/v3.10/source/init/main.c 的 start_kernel() 方法中不仅有上述初始化“墙上时间”的过程,还会调用 tick_init()、init_timers()、hrtimers_init()、time_init() 等方法来建立计时体系结构,分别注册通知链、初始化软件时钟相关数据结构、初始化高精度定时器、初始化各种时间源。各个方法都有独特的用途,以及严丝合缝的配合,有兴趣的同学可以阅读源码,在此不进行展开(实在是太多了==)。
4.1.2. 系统时间的读取
系统时间是通过 getnstimeofday() 方法读取的,在上文中已经详细介绍了vDSO的读取方法,其中还加入了高精度定时器的读取。在 linux/v3.10/source/kernel/time/timekeeping.c 中可以看到单纯系统中 getnstimeofday() 的实现:
int __getnstimeofday(struct timespec *ts)
{
struct timekeeper *tk = &timekeeper;
unsigned long seq;
s64 nsecs = 0;
do {
seq = read_seqcount_begin(&timekeeper_seq);
ts->tv_sec = tk->xtime_sec;
nsecs = timekeeping_get_ns(tk);
} while (read_seqcount_retry(&timekeeper_seq, seq));
ts->tv_nsec = 0;
timespec_add_ns(ts, nsecs);
return 0;
}源码已经很清楚了,不过多解释。值得一提的是 __getnstimeofday() 是顺序锁的典型应用,“写请求并发相对较少,写锁必须优先于读锁”,这样的特点使用顺序锁大大提高了效率。
4.1.3. 系统时间的更新
所谓“前人栽树后人乘凉”,读取效率高是因为有后台线程一直在更新xtime变量。更新过程是怎样的?linux/v3.10/source/kernel/time/timekeeping.c#L489 中的 do_settimeofday() 方法(部分):
int do_settimeofday(const struct timespec *tv)
{
struct timekeeper *tk = &timekeeper;
struct timespec ts_delta, xt;
unsigned long flags;
// 获取写锁
raw_spin_lock_irqsave(&timekeeper_lock, flags);
write_seqcount_begin(&timekeeper_seq);
// 更新时间
timekeeping_forward_now(tk);
xt = tk_xtime(tk);
ts_delta.tv_sec = tv->tv_sec - xt.tv_sec;
ts_delta.tv_nsec = tv->tv_nsec - xt.tv_nsec;
tk_set_wall_to_mono(tk, timespec_sub(tk->wall_to_monotonic, ts_delta));
tk_set_xtime(tk, tv);
timekeeping_update(tk, true, true);
// 释放写锁
write_seqcount_end(&timekeeper_seq);
raw_spin_unlock_irqrestore(&timekeeper_lock, flags);
return 0;
}每一个时钟中断(节拍)便会更新一次,很清晰的 “获取写锁 -> 更新时间 -> 释放写锁” 的过程。
4.2. 定时器
定时器顾名思义,是一种软件功能,即允许在将来的某个时刻,函数在给定的时间间隔用完时被调用。这是一个真正的重头戏,各种系统中的事件都依赖于定时器去完成。
定时器分为静态定时器和动态定时器,静态定时器一般执行一些周期性的固定工作,如更新系统运行时间、更新实际时间、平衡各个处理器上的运行队列、检查进程时间片、更新各种统计值等。
动态定时器被动态地创建和撤销。由于硬件定时器的有限性,动态定时器应用更为广泛,故我们着重对动态定时器进行展开。
4.2.1. 相关数据结构
4.2.2.1. HZ
节拍率(HZ)是时钟中断的频率,表示一秒内时钟中断的次数。HZ值一般与体系结构有关,常设置为100。HZ值高则时钟中断程序运行的更加频繁,依赖时间执行的程序更加精确,对资源消耗和系统运行时间的统计更加精确;同时,时钟中断执行的频繁会占用的CPU时间过多,增加系统负担。
4.2.2.2. jiffies
jiffies变量是一个计数器,用来记录自系统启动以来产生的节拍总数。
在 linux/v3.10/source/include/linux/jiffies.h 中查看定义:
/* * The 64-bit value is not atomic - you MUST NOT read it * without sampling the sequence number in jiffies_lock. * get_jiffies_64() will do this for you as appropriate. */ extern u64 __jiffy_data jiffies_64; extern unsigned long volatile __jiffy_data jiffies;
每次时钟中断(节拍)发生它便加一,32位的 jiffies 最大值为 (2^32 - 1),因此每隔大约50天便会回绕一次。为了避免此问题,jiffies在启动时并不是被指定为0,而是指定为 (-300*HZ) ,因此,计数器将会在系统启动后的5分钟内处于溢出状态,使得没有做溢出检测的内核代码在开发阶段被及时地发现。在 linux/v3.10/source/include/linux/jiffies.h#L162 中可以找到该定义:
/* * Have the 32 bit jiffies value wrap 5 minutes after boot * so jiffies wrap bugs show up earlier. */ #define INITIAL_JIFFIES ((unsigned long)(unsigned int) (-300*HZ))
不仅如此,Linux还定义了time_after、time_after_eq、time_before、time_before_eq等宏处理回绕问题。其实可以类比为将 unsigned long 类型转换为 long 类型,在1ms为一个节拍的情况下,jiffies_64需要数十亿年才会发生回绕,巧妙地解决了此问题。
4.2.2.3. timer_list
动态定时器用 timer_list 数据结构表示,该数据结构在 /linux/v3.10/source/include/linux/timer.h#L12 中定义如下(部分):
struct timer_list {
struct list_head entry;
unsigned long expires;
struct tvec_base *base;
void (*function)(unsigned long);
unsigned long data;
};其中,entry字段用于将软定时器插入链表中,后文将详细介绍相关算法;expire字段指定定时器的到期时间,用节拍数表示,其值为系统启动以来所经过的节拍数,当expire的值小于或等于jiffies的值时,就说明定时器到期或终止;function字段包含定时器到期执行函数的地址;data字段指定传递给定时器函数的参数。
4.2.2. 动态定时器算法
讲过动态定时器的表示方法,接下来讲动态定时器的工作算法。定时器的三个操作:添加 (add_timer)、删除 (del_timer) 以及到期处理(tick 中断)都对精度和延迟有巨大影响,而其精度和延迟又对应用有巨大影响。Linux在定时器的处理上经历了几个阶段:
4.2.2.1. “原始”算法
简单考虑,动态定时器被定义为一个带指针的数据结构,那么只需要一个全局的链表即可存储所有动态定时器。每次需要新的timer时,只需要向这个链表中添加一个 timer_list 元素,每个节拍到来时遍历该链表。但是显然,一个无序链表元素数量增加时遍历的成本会线性增加,增、删、到期的时间复杂度分别为O(1)、O(n)、O(n),计算机中会存在极大数量的定时器,不理想。
4.2.2.2. 排序后的算法
自然而然想到在插入链表时排序,增、删、到期的时间复杂度分别为O(n)、O(1)、O(1),虽然到期处理请求快了一些,但是整体还不理想。
4.2.2.3. 最小堆算法
最小堆是我们熟悉的数据结构,利用最小堆可以在链表排序的基础上进一步减小新增定时器的操作复杂度。增、删、到期的时间复杂度分别为O(logn)、O(1)、O(1)。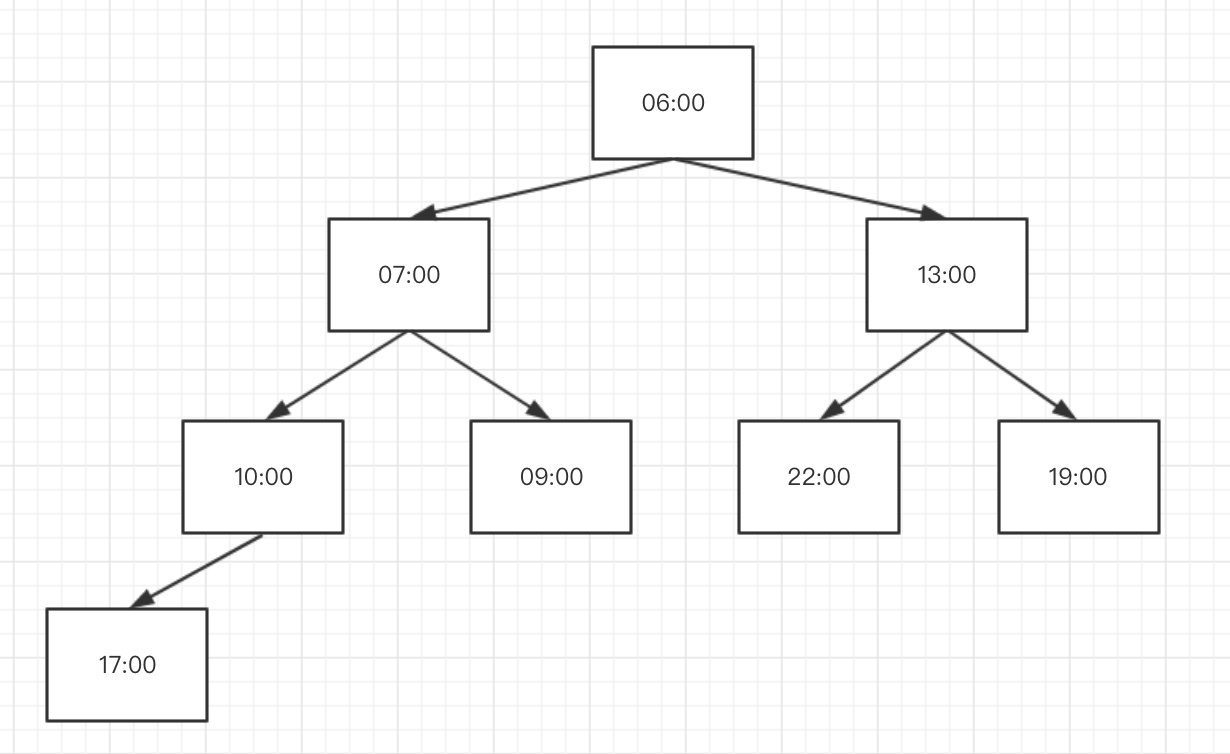
4.2.2.4. 时间轮算法
时间轮算法并不会遍历每一个定时器节点,而是将定时器按照到期时间分配到各个节拍上,随着时钟的增加,如果发现该节拍上存在定时器则该定时器到期。这样形成一个类似轮状结构,轮上每一个节点对应一个链表或数组,节点的间隔就是定时器最小时间区分。示意图如下:
如图所示,轮中共有N个bucket,每个bucket代表一秒(只作为示意,实际精度很高),每个bucket对应一个链表,链表中为当前bucket将要到期的定时器对象。中间的指针被称为cursor,cursor指向bucket时则bucket对应的链表全部做到期处理。
这样一来,增、删、到期的时间复杂度全部为O(1)。该算法的图中圆轮可以通过数组实现。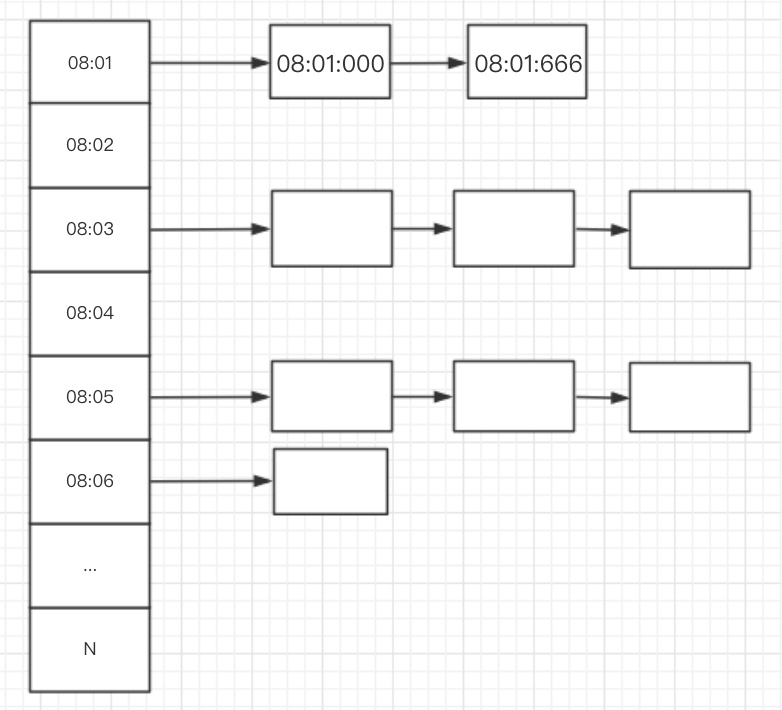
时间复杂度上达到预期,可惜这个算法有一个致命的缺陷,当时间线被拉长,精度提高,图中的N将会非常大,数组需要巨大的内存消耗,这显然是不现实的。
4.2.2.5. 分层时间轮算法
分层时间轮(Hierarchical Timing Wheels)算法是在时间轮的基础上做了改进,将单一的 bucket 数组分成了几个不同的数组,每个数组表示不同的时间精度。示意图如下所示:
上图的一个分层时间轮有三级,分别表示小时、分钟和秒。在小时数组中,每个 bucket 代表一个小时。采用原始的时间轮如果我们要表示一天,且 bucket 精度为一秒时,我们需要 24 * 60 * 60 = 86400 个 bucket;而采用分层时间轮,我们只需要 24 + 60 + 60 = 144 个 bucket。极大地减小了空间复杂度,同时增、删、到期的时间复杂度全部为O(1)。
看上去像一个完美的算法,实际并不然。当每次秒钟数组复位时,下一分钟的定时器需要重排列到各个秒钟bucket中,每次分钟数组复位时同样,这个操作被称为“cascades”。举例说明,比如当前时间是早上08:00:00,要添加一个早上09:05:58触发的定时器,则该定时器刚添加时指针是挂在小时数组中09的位置的;当08:59:59过去后,将挂在小时数组中09位置的所有定时器按照到期的分钟数排列到分钟数组中;当09:04:59秒过去后,将挂在分钟数组中05位置的所有定时器按照到期的秒钟数排列到秒钟数组中。则该09:05:58触发的定时器被分配到了秒钟数组的58位置。当cursor经过该位置时,定时器被触发。每次cascades操作的时间复杂度是O(m),该m为每个bucket中定时器的个数,多数情况下 m 远小于系统中所有定时器个数。
4.2.2.6. 红黑树算法
实时应用、多媒体软件对时钟和定时器的精度要求不断提高,在早期 Linux 内核中,定时器所能支持的最高精度是一个 tick。为了提高时钟精度,人们只能提高内核的 HZ 值,更高的 HZ 值意味着时钟中断更加频繁,内核要花更多的时间进行时钟处理。同时,高精度时钟硬件的出现对于定时器算法也提出了更高的要求。
虽然时间轮是一种有效的管理数据结构,但其 cascades 操作有不可预料的延迟。它更适于被称为“timeout”类型的低精度定时器,即不等触发便被取消的 Timer。这种情况下,cascades 可能造成的时钟到期延误不会有任何不利影响,因为根本等不到 cascades,换句话说,多数 Timer 都不会触发 cascades 操作。而高精度定时器的用户往往是需要等待其精确地被触发,执行对时间敏感的任务,因此 cascades 操作带来的延迟是无法接受的。所以内核开发人员不得不放弃时间轮算法,转而寻求其他的高精度时钟算法,最终开发人员选择了内核中最常用的高性能查找算法:红黑树来实现 hrtimer。
所有的 hrtimer 实例都被保存在红黑树中,添加 Timer 就是在红黑树中添加新的节点;删除 Timer 就是删除树节点。红黑树的值为到期时间。Timer 的触发和设置管理不在定期的 tick 中断中进行,而是动态调整:当前 Timer 触发后,在中断处理的时候,将高精度时钟硬件的下次中断触发时间设置为红黑树中最早到期的 Timer 的时间。时钟到期后从红黑树中得到下一个 Timer 的到期时间,并设置硬件,如此循环反复。
4.2.2.7. 延迟函数
严格来讲延迟函数并不应该归在这一小节,因为并不属于动态定时器的演化范围。但是它也是一种定时器的实现方式,故在此简单讲解。
当内核需要等待一个较短的时间间隔,如不超过毫秒时,就无需使用动态定时器,且动态定时器由于相对较大的设置开销也是不精确的。在这些情况下,内核使用 udelay() 或 ndelay() 函数,接收一个微秒或纳秒级别的参数,并在延迟结束后返回。如果可以利用TSC或HPET硬件,则该方法使用它们来获得精确的时间测量,否则该方法会执行一个紧凑指令循环的n次循环,至到达指定时间。
5. 时钟振荡器硬件
上文中所有都还停留在软件和集成硬件层面,我们常说“节拍到来时触发何种操作”,可是节拍是如何产生的?芯片本身通常并不具备时钟信号源,因此须由专门的振荡电路提供时钟信号。说起振荡,我们脑海里第一反应可能是高中学习的LC振荡器,通过电场和磁场的周期性变化产生固定的频率:
根据这个简单的原理产生了EE专业传世经典:NE555定时器芯片
当然这是经典的实现方式,但是如今计算机中常用的时钟振荡源是晶体振荡器,也就是我们常说的“晶振”。
石英晶体振荡器(Quartz Crystal OSC)是一种最常用的时钟信号振荡源。石英晶体就是纯净的二氧化硅,是二氧化硅的单晶体。从一块晶体上按一定的方位角切下薄片(称为"晶片"),在晶片的两个表面上涂覆一层薄薄的银层后接上一对金属板,焊接引脚,并用金属外壳封装,就构成了石英晶体振荡器。
石英晶片之所以能当为振荡器使用,是基于它的压电效应:在晶片的两个极上加电场,会使晶体产生机械变形;在石英晶片上加上交变电压,晶体就会产生机械振动,同时机械变形振动又会产生交变电场,虽然这种交变电场的电压极其微弱,但其振动频率是十分稳定的。
为什么石英晶片会有压电效应?下面是唐僧念经可以不看==
石英是日常最常见的非线性晶体,来源于硅氧四面体不能完美密堆积而产生的各种晶胞构象。由有潜在极性的硅氧四面体规则堆积成晶体,所以在某些晶面上,石英整体会呈现极性,并因为电荷的规则分层排布成为电介质。当外加电压的时候,石英晶体会发挥电介质的特性,让硅氧四面体变形来极化自己,从而抵消外加的电场,在此过程中产生力学特性。相反,当石英晶体受力的时候,晶胞参数就会改变,使其极性变化,从而硅氧四面体和石英本身的介电常数改变,这样一来再受电场的时候,因为其介电常数变化,就会使得电容变化,可以测得电压变化,形变的弹性也会改变。这就是压电晶体的正压电和反压电效应。当固定的晶体受力的时候,当然会回弹产生振动。如果外加电场也周期性变化,使得晶体周期性受力,和石英晶体的固有频率相同,那么晶体就会受到电场而反复振动,反过来增强电场,形成谐振。
由于我们的主攻方向是软件层面,辛勤的EE工程师为我们提供了有力的硬件保障,所以关于实际底层硬件就不再多讲,感兴趣的同学可以自行继续研究模电数电等知识。
6. 总结与思考
6.1. 文章总结
本篇文章接续上篇-应用篇,从系统和硬件的角度着重讲解了在高级语言之下的层次,时间和日期的相关问题。
首先从问题探究的角度,抛出了不同系统中 System.currentTimeMillis() 方法调用的时间成本相差巨大的问题,并从此问题入手深入探究了 Windows 和 Linux 系统中 System.currentTimeMillis() 方法的执行流程,也即上层对系统时间点的获取过程,并解释了文首的问题。
之后,根据延续该问题引出的硬件时钟概念,介绍了系统中主要的几种时间相关硬件,包括实时时钟、计数器、高精度定时器等。同时介绍了Linux系统对于不同硬件的数据结构表示管理方法,及不同硬件时间源的比较。
接下来以Linux为例,介绍了系统的计时体系结构,主要包括系统时间和定时器。系统时间包括时间点的初始化、获取、更新方法。定时器介绍了相关的概念和数据结构,着重讲解了动态定时器算法的演进过程,从演进过程中可以看出Linux对于系统的一步步优化。
最后,简要介绍了时钟的最底层来源——时钟振荡器硬件,以及它的原理压电效应,从而基本打通了从应用层到硬件层的时间相关原理。
6.2. 反思回顾
全文(包含应用篇和系统&硬件篇)是从实际开发的角度出发的,按照从顶层向底层的角度进行介绍。但是实际的历史是自下而上发展的,先有了基础的物理学支撑和电子硬件支撑,才能发展出上层至高级语言和数据库技术的应用,应用的需求进而倒逼硬件的发展。技术发展进步是迅速的,一个个框架更新换代,一个个新技术不断涌现,但是很多底层原理鲜有改变,这也是我们努力的方向,厚积才能薄发,掌握基本原理才能更好更快地学习从而跟上时代技术进步。
本文Linux版本是v3.10,每个版本的实现方式都有一定差异,此次深入探索只是讲出了大致的思想方法,具体版本还需要读者自己查看对应源码。
时间和节拍是计算机系统运行的根基,相关概念、原理、源码等车载斗量。本篇文章虽篇幅较长,但是并不能详尽的解释系统所有关于日期时间的问题,只是捡拾了笔者认为需要关注的一些点,更多的问题欢迎大家一同探讨。
在写文章过程中,越向底层探究越发现参考资料变少,很多问题想搞清楚要通过阅读源码来解决。而自己阅读源码的功力不足,加之本身知识经验有限,所以可能某些问题上理解不恰当或表述不清楚,欢迎大家指正。
7. 参考资料
《深入理解Linux内核》第六章-定时测量
首发于https://mp.weixin.qq.com/s/cN1PrKaBoAe-b7RXSqh9iQ。转载请注明出处。

最新评论: